Last year I published a blog post focusing on the JSON parser available in vRealize Log Insight (https://thomas-kopton.de/vblog/?p=144) and I believe this could have been a beginning of a series – “vRLI Parsers “.
In this post I will show how to configure and utilize the CSV parser using a very prominent and media-effective use case:
COVID-19 aka Coronavirus!
The needed data is publicly available, e.g. here:
https://github.com/CSSEGISandData/COVID-19 The actual data sources are listed on the GitHub project page and the data itself is already in the format we need to feed it into vRLI – CSV files.
Data Review
The time series data files provided by CSSE are in the following format:

Or shown as raw data:

vRealize Log Insight processes every single CSV row as one message and if we do not specify our own timestamp as part of the message, vRLI will use the ingestion time as the timestamp for the message. This is clearly nothing we would like to have in order to have some meaningful diagrams showing us e.g. how the virus spreads in various countries. We will change the timestamp accordingly.
We also see that the original data contains “,” signs as part of province or state names, this is not compatible with the vRLI CSV parser as it would change the number and content of the fields. I have used Numbers on my Mac to “clean up” the file and replace the real “,” field separation signs with “;”.
To ingest the data, we will use the vRLI agent and an appropriate configuration of the agent.
vRLI Agent Config
My setup in for this use case is:
- vRLI 8.0.0-14870409
- vRLI agent 8.0.0.14743436
- vRLI agent installed on a Debian OS
- Agent successfully connected to vRLI
The configuration of the agent to parse CSV files is general pretty simple.
[filelog|some_csv_logs]
directory=/tmp/corona-data
include=*.txt;*.csv
parser=mycsv
[parser|mycsv]
base_parser=csv
delimiter = ";"
debug=yes
fields=timestamp,testrun,location,country,confnumber
field_decoder={"timestamp":"tsp_parser"}
[parser|tsp_parser]
base_parser=timestamp
debug=yes
;format=%Y-%m-%d %H:%M:%S
format=%s
Let us take the configuration to pieces and analyze what the single parts are doing. The first four lines, 1 – 4, contains the main section telling vRLI where to look for specified files and what parser to use to process the messages stored in those files. The parser is not specified directly as one of the OOB parsers but as a parser section.

Lines 6 – 11 contains the actual parser configuration. In this section we specify the base parser, means one of the parsers available in vRLI. In our case csv.
Line 10 describes how to name the fields extracted from every row in a CSV file, separated by “;” in my case. The specification of fields has to match exactly the number of fields in the file we want to parse, and every single line of the file needs to have exactly the same number of fields. The fields itself might be empty. In this case we expect lines in our csv file containing exactly five values separated by “;”.
We assume the first value is a timestamp, the second one will be a number we will use later on to filter for messages in vRLI in case we ingest the same set of data several times, like every day. Location and country are pretty clear and “confnumber” is the actual number of confirmed cases as in the repository by Johns Hopkins CSSE. Line 11 specifies a special decoder for a field extracted in line 10 – here we will use a special decoder to decode or parse the timestamp.

Lines 13 – 14 specifies our decoder for the timestamp field. A decoder is just another term for parser. As for every parser we specify the base parser, line 14. Line 17 tells the timestamp parser how to process the value in the “timestamp” field. In this case we expect the value to be an UNIX epoch timestamp.

With this configuration we expect the data in a csv file to have the following format (example):
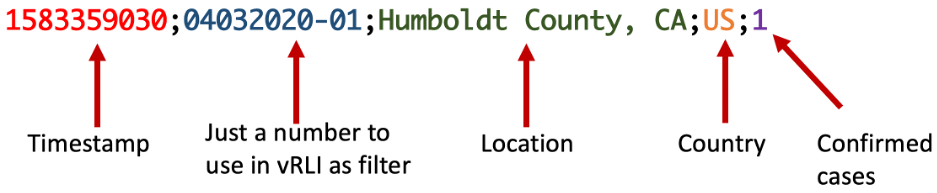
I am using the timestamp instead of the date as in the original file because:
- The format used by Johns Hopkins CSSE is not optimal for the vRLI timestamp parser
- I want to see all data in a short time frame in vRLI. The goal is to have a fancy diagram to compare the numbers across different countries.
We will replace the original timestamps, which are day per data point, with 10ms steps per data point.
Format Adjustment
As we can see, the original csv file needs to be “slightly” adjusted to be correctly parsed by the parser we configured.
This is pretty easy to achieve with few lines. PowerShell, Bash or in my case vRO:

This very simple workflow can be found on VMware Code soon. I will update the link shortly.
Data Import
Now we are ready to let vRealize Log Insight do the job. Just put the new csv file into the specified folder on the box where you have configured the vRLI agent, wait few seconds, every day in the original file is a second in the parsed file, and analyze the numbers.
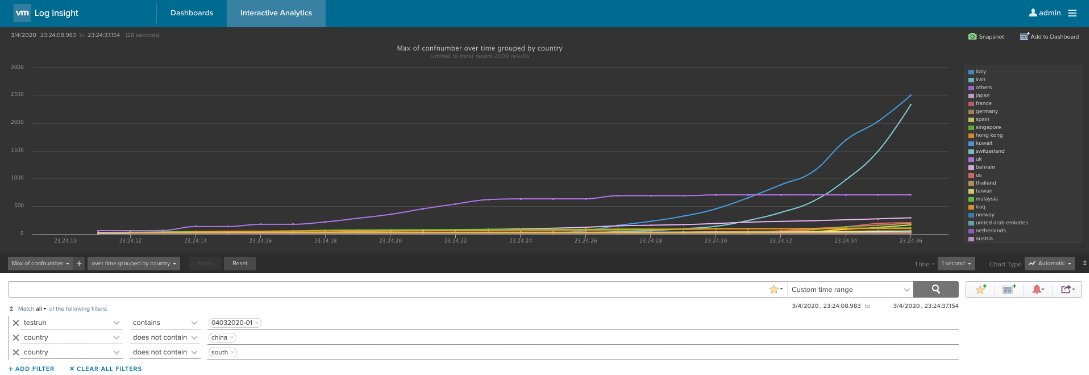
Figure 7: vRLI analyzing Coronavirus data – 1
Let’s see how we are doing here in Germany compared to Italy and US:

Stay safe!
Thomas – https://twitter.com/ThomasKopton