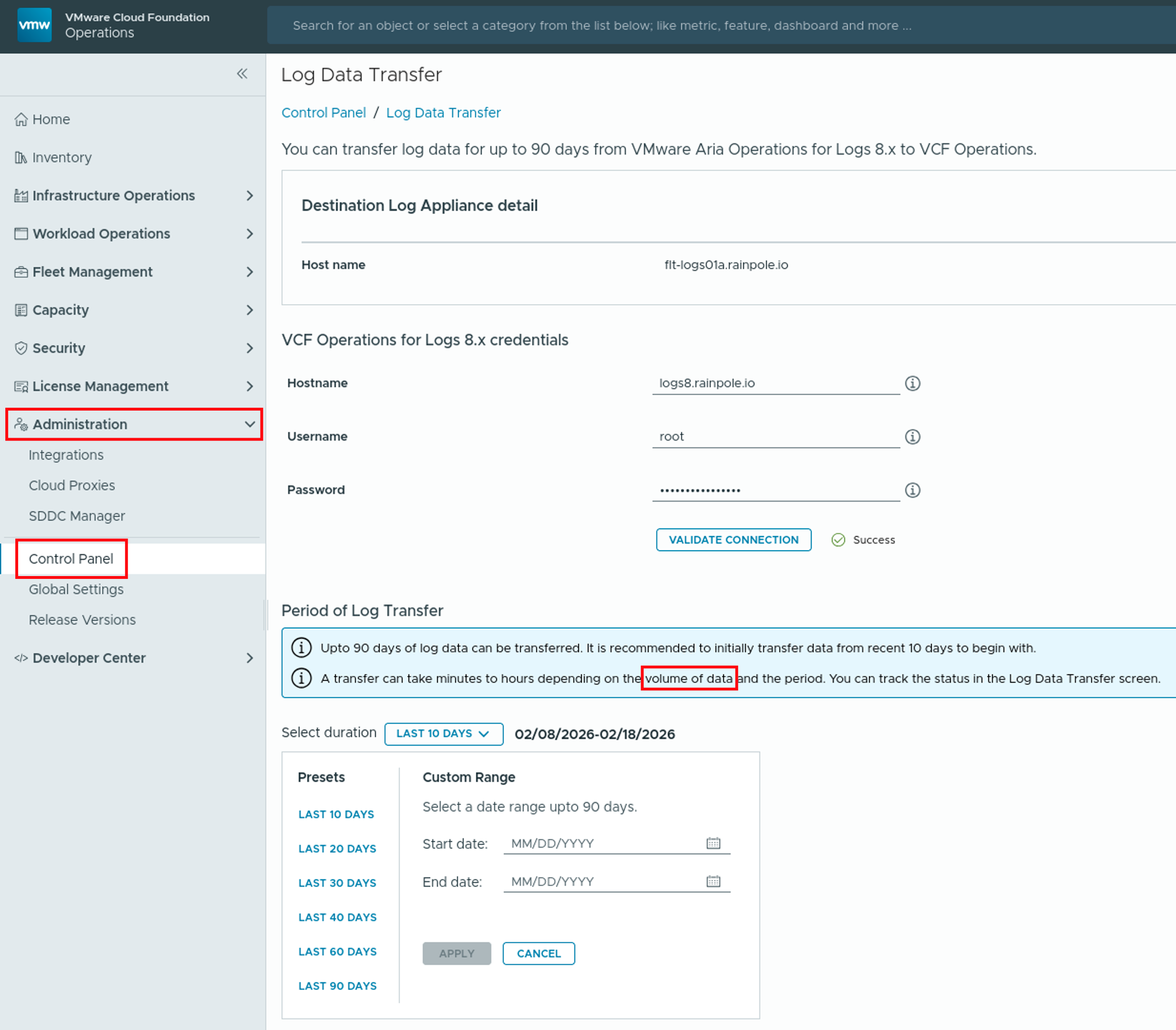
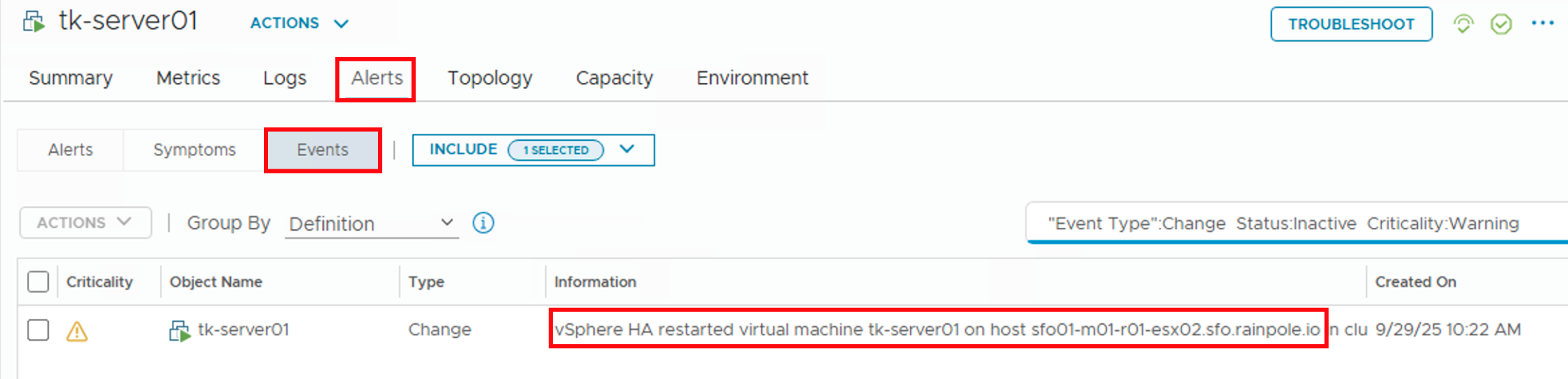
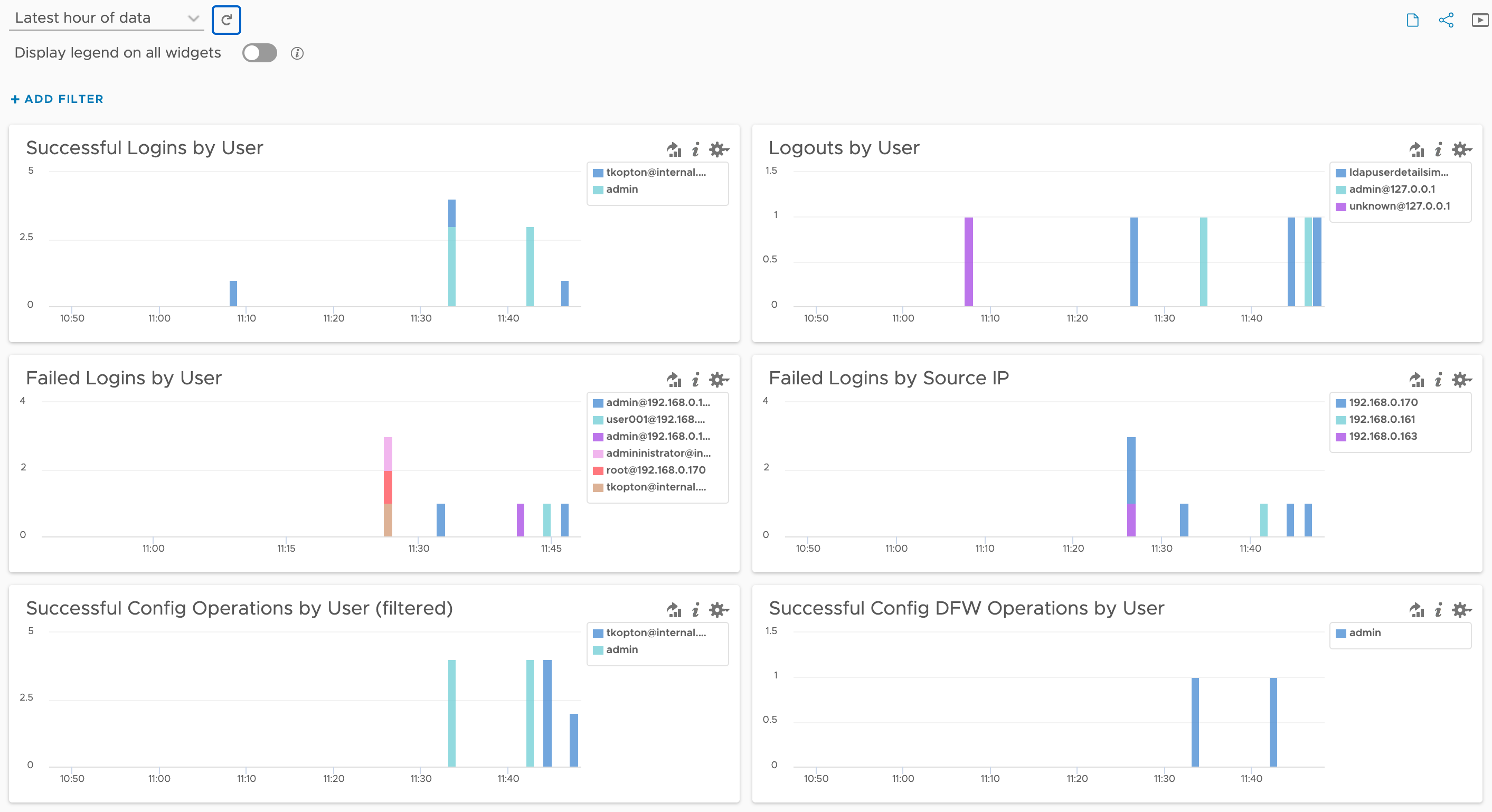
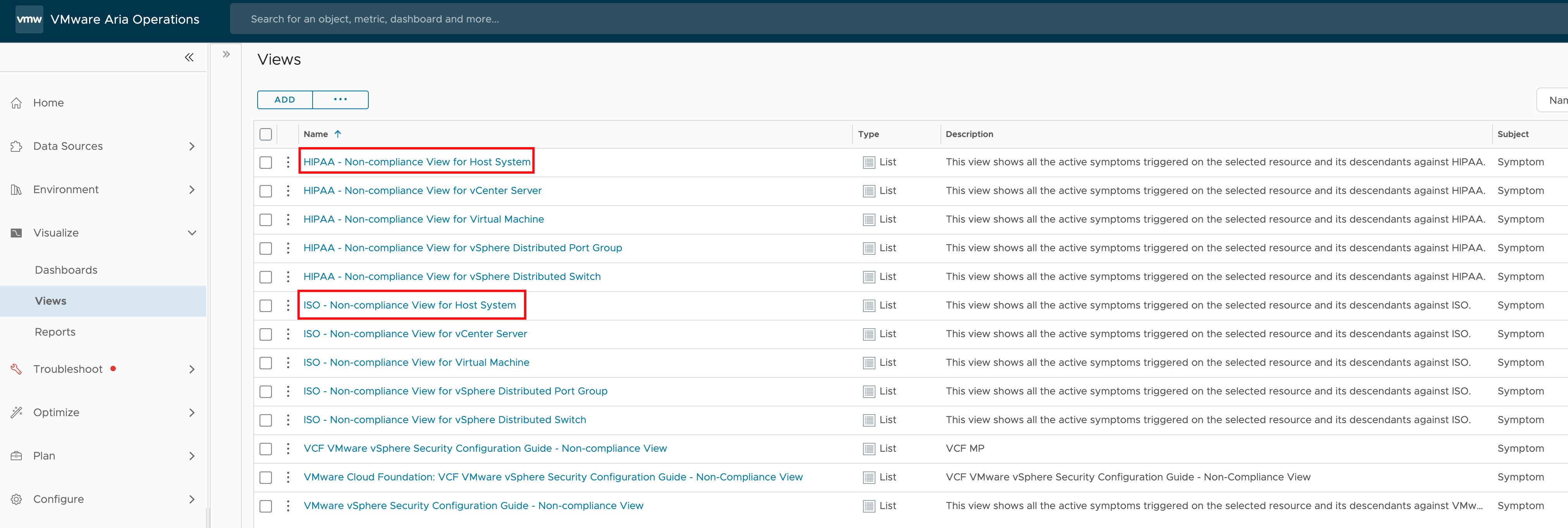
Introduction to Log Data Transfer in VCF Operations 9 With the release of VMware Cloud Foundation (VCF) 9, Logs is now more integrated into Operations. Moving from Aria Operations for Logs 8.18.x to VCF 9 does not support a direct, in-place upgrade, instead, administrators must perform a fresh deployment of the 9.0 appliance. This deployment …
Log Data Transfer from Aria Operations for Logs 8.18 to VCF Operations for Logs 9