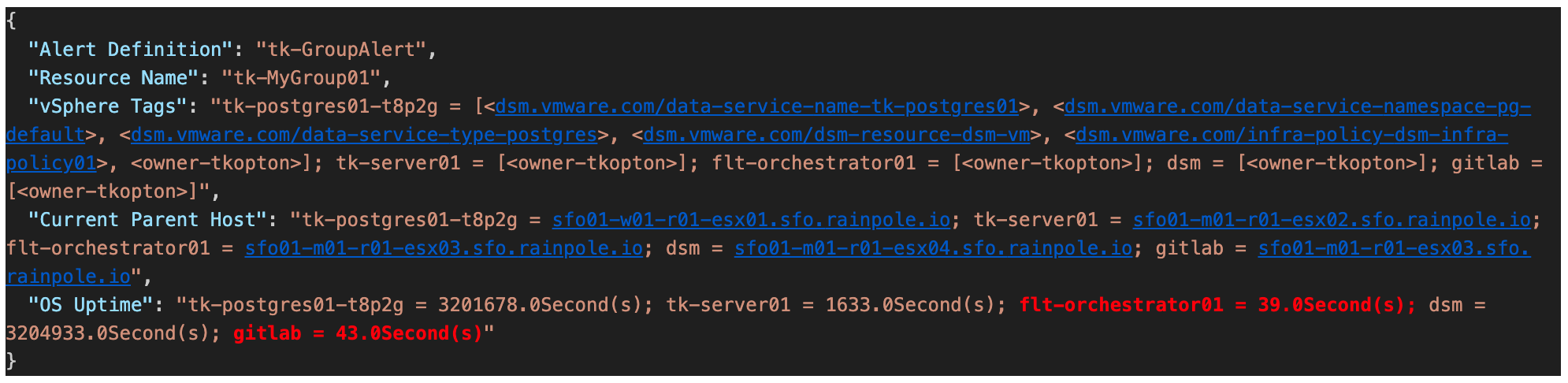
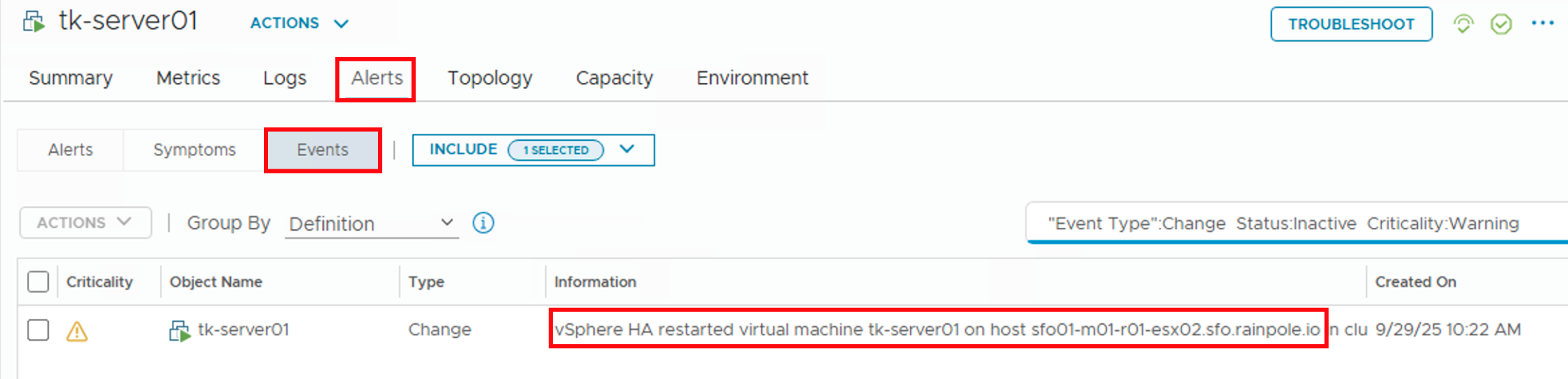
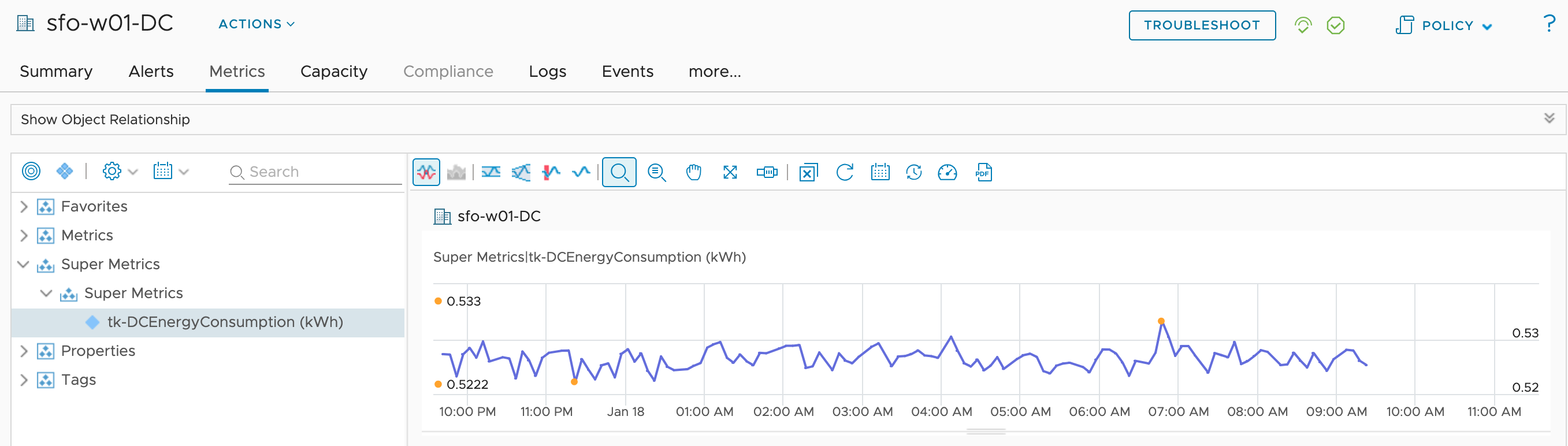
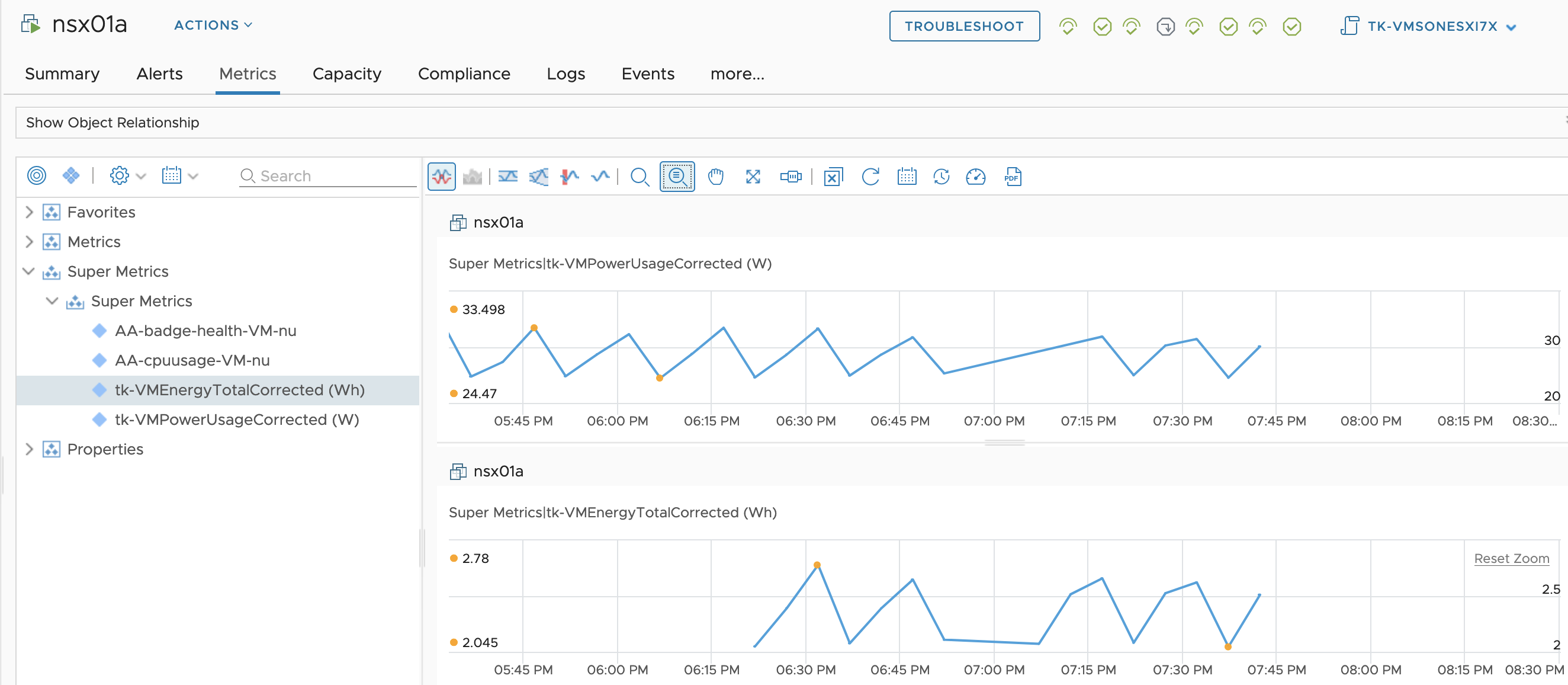
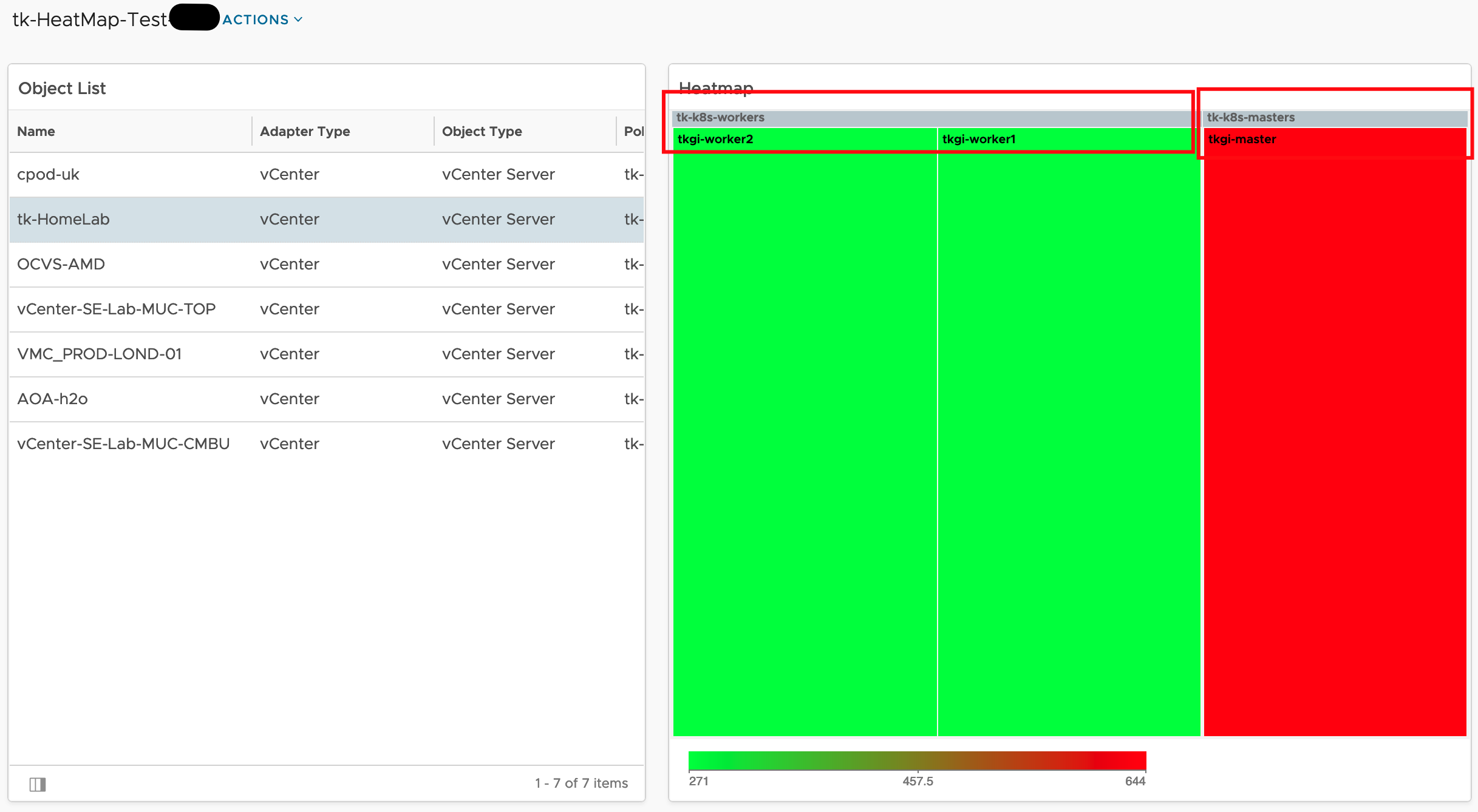
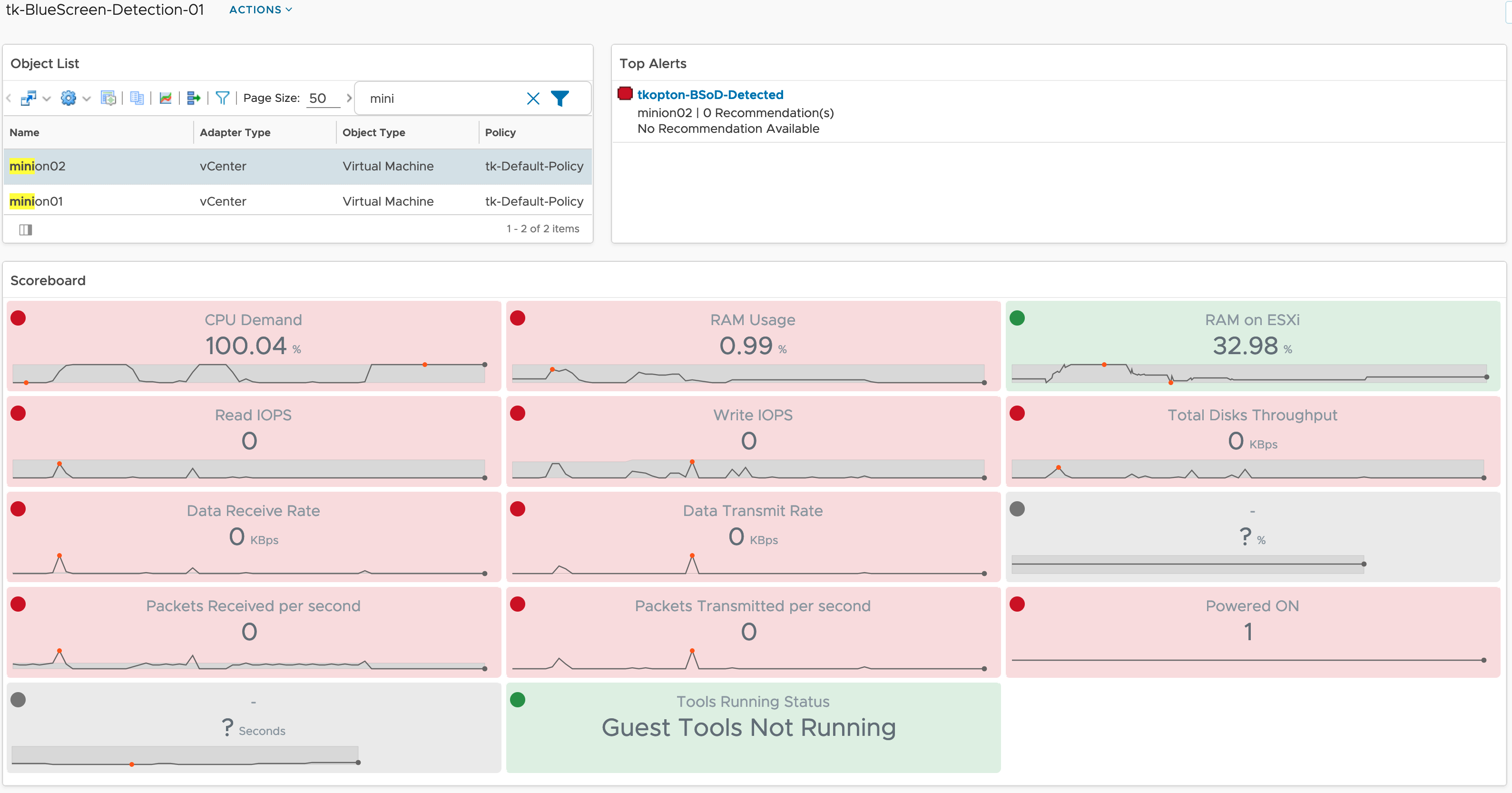
In my previous post (https://thomas-kopton.de/vblog/?p=2198), I detailed how to track HA-induced Virtual Machine restarts in VCF Operations, including the required symptoms, alert definitions, and REST Webhook notifications. However, in larger setups, with potentially over 20 VMs per ESX host, receiving 20 individual notifications is impractical. This simply creates alert fatigue and undermines the entire alerting …
Reducing Alert Noise for VM Groups in VCF Operations