In my previous post (https://thomas-kopton.de/vblog/?p=2198), I detailed how to track HA-induced Virtual Machine restarts in VCF Operations, including the required symptoms, alert definitions, and REST Webhook notifications. However, in larger setups, with potentially over 20 VMs per ESX host, receiving 20 individual notifications is impractical. This simply creates alert fatigue and undermines the entire alerting process.
A better approach is clearly essential.
Scenario
The scenario we know from the previous post is still quite simple, and some of the requirements are already fulfilled :
- The owners should be notified via a REST Webhook – we already know how to do this for every single VM.
- Each host can run VMs from different owners.
- Each VM has the owner recorded in its metadata, in this case as a vSphere Tag
- The owners want to be informed when their VMs are restarted by an HA event on a different ESX host and receive only one notification in case of HA event affecting multiple Virtual Machines.
Solution
Since we can easily differentiate VMs by their metadata, and VCF Operations provides us with the tool of Custom Groups, the solution path is already clear. Instead of sending an individual notification for every single VM, we will now send just one for the entire group whenever one or more VMs within that group have been affected by an HA event. This, admittedly, is a compromise between receiving 20 or more individual notifications and getting a single notification for the whole group, even if only one Virtual Machine was impacted. We will now explore how to effectively deal with this.
Custom Groups Configuration
First, we need the appropriate metadata on our VMs. In my case, these are vSphere Tags, as shown in the following image. To keep it simple, I’ve used two tags that represent the owner of a VM. With these, we can very easily create corresponding Custom Groups.
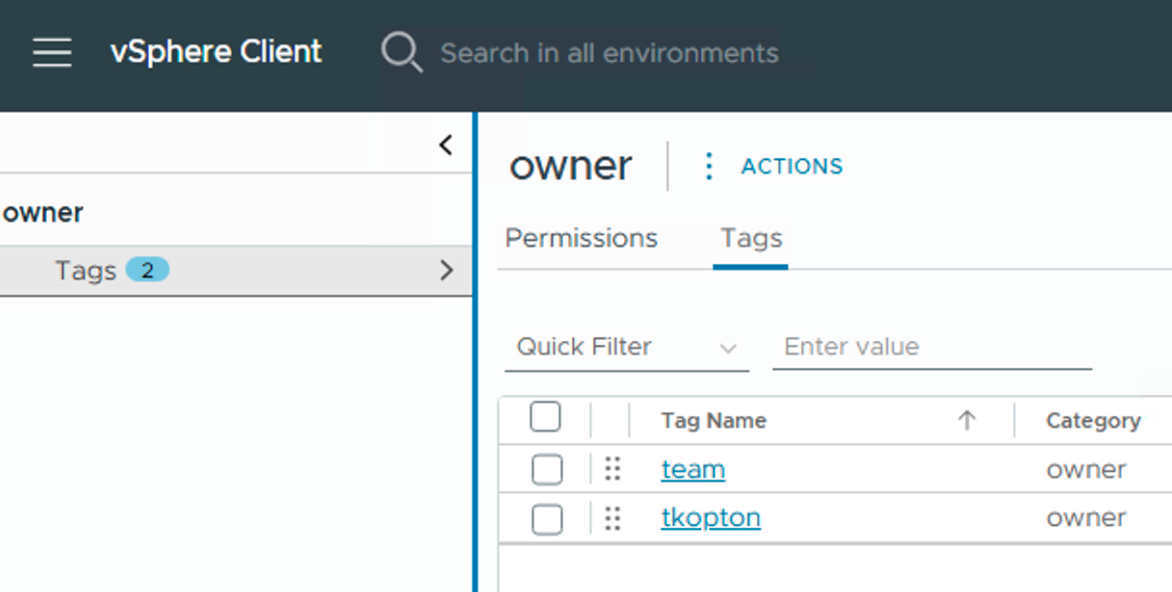
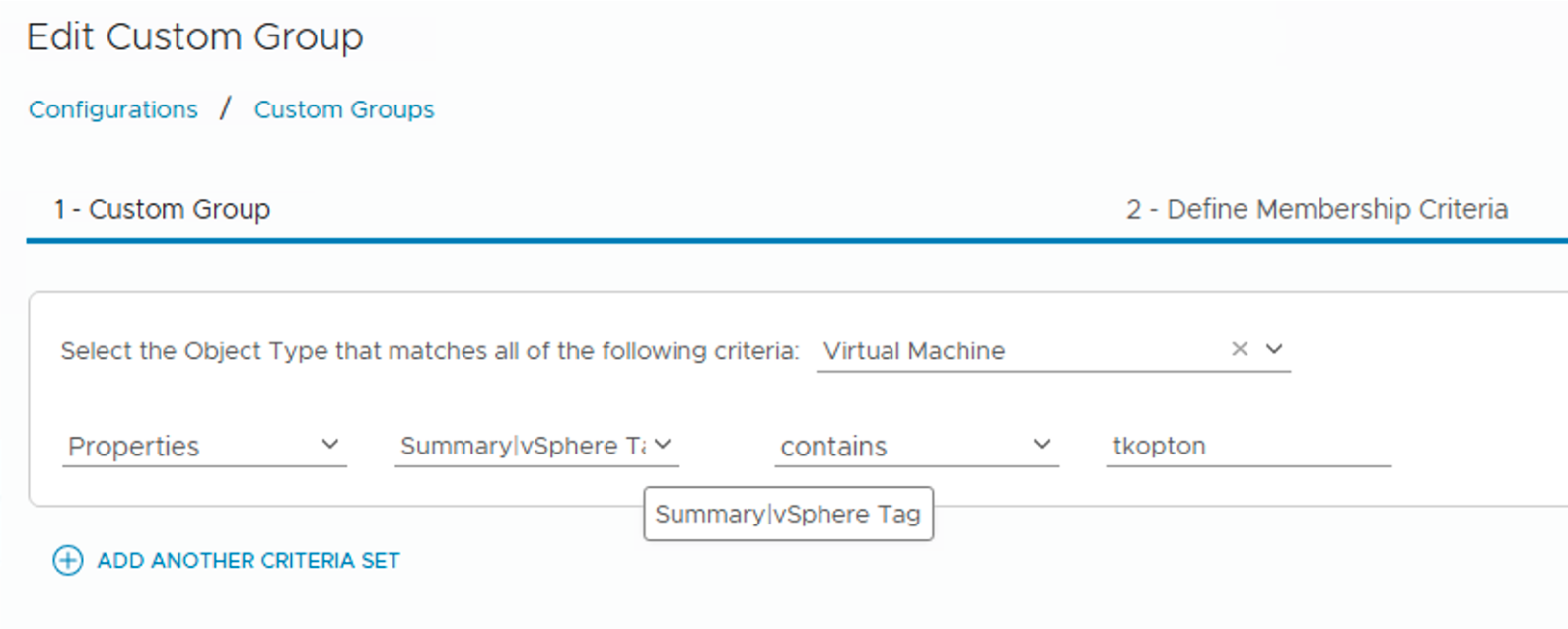
The next image shows the configuration of one of the two Custom Groups. The key here is the correct selection of the Membership Criteria to automatically and dynamically include all VMs that are tagged with the appropriate vSphere Tag during their lifecycle. It’s also important to note that the Custom Group members are updated every 20 minutes.
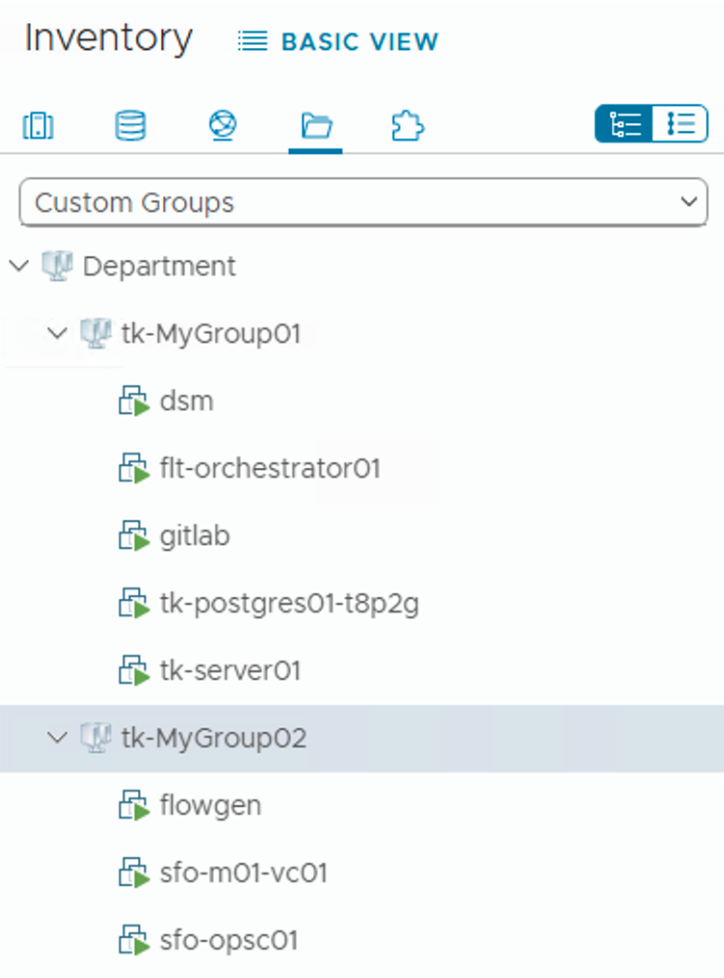
Below, you can see my two Custom Groups, one for each distinct owner, and their associated VMs.
Payload Template
Building on the previous post, we now need to modify three key components: the Notification, the Payload Template and we need a new Alert Definition. Previously, notifications were directly triggered by alarms on individual VMs. Now, this logic needs to apply to an entire group of VMs. Since a Custom Group is now the target object type, the Payload will also need a slight reconfiguration.
Let’s start with the new Webhook Payload Template.
In the next screenshot, we see that this time, the Custom Group is the primary object type, taking center stage. To include the data of the VMs within the group in the payload, the Virtual Machine object type is configured as a descendant. This allows us to add any other desired metrics and properties to the JSON body.

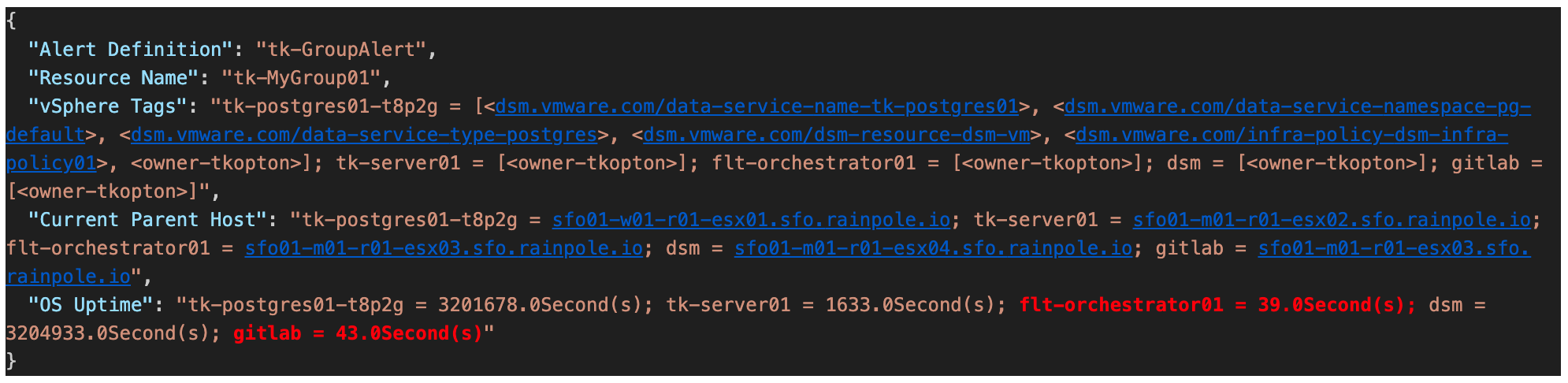
I specifically included the OS Uptime metric. This could be key to identifying which specific VM(s) in the group were likely restarted by an HA event. We could also add and evaluate the various Alert Count metrics available for each object (including VMs). This would allow us to later focus only on VMs with, for instance, an Alert Count Critical metric greater than 0.
Alert Definition
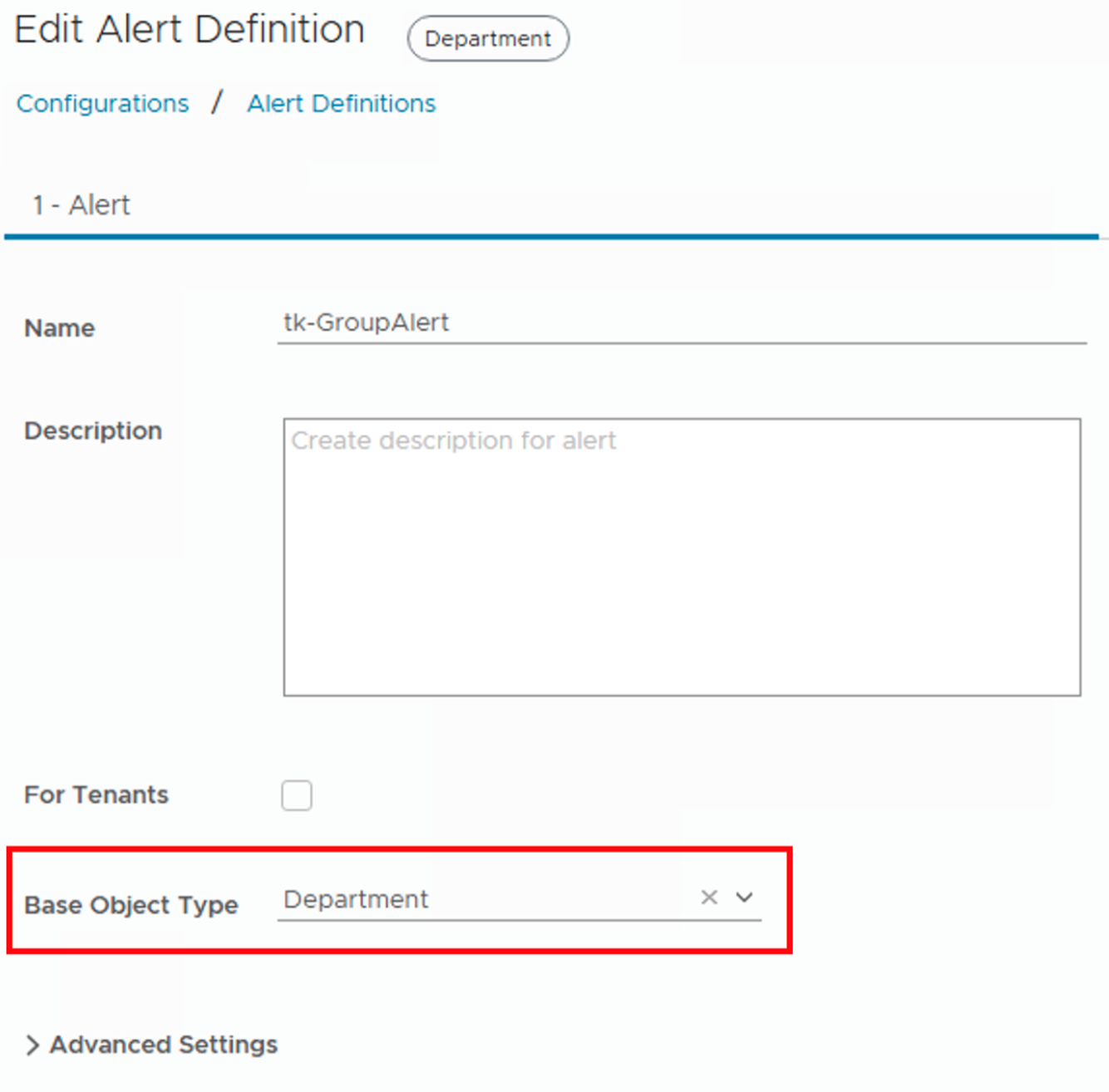
To alarm at the Custom Group level, we need a new Alert Definition, though it’s quite similar to the one from our previous post. The image below displays this definition, with the Base Object set to the type of my Custom Groups. An alternative approach would have been to create an entirely new Group Type before building the Custom Groups themselves. And because we need to use an event-based symptom from the Virtual Machine Object Type, we select Child Object Virtual Machine for the symptom’s actual definition, as you’ll see in the second image below.
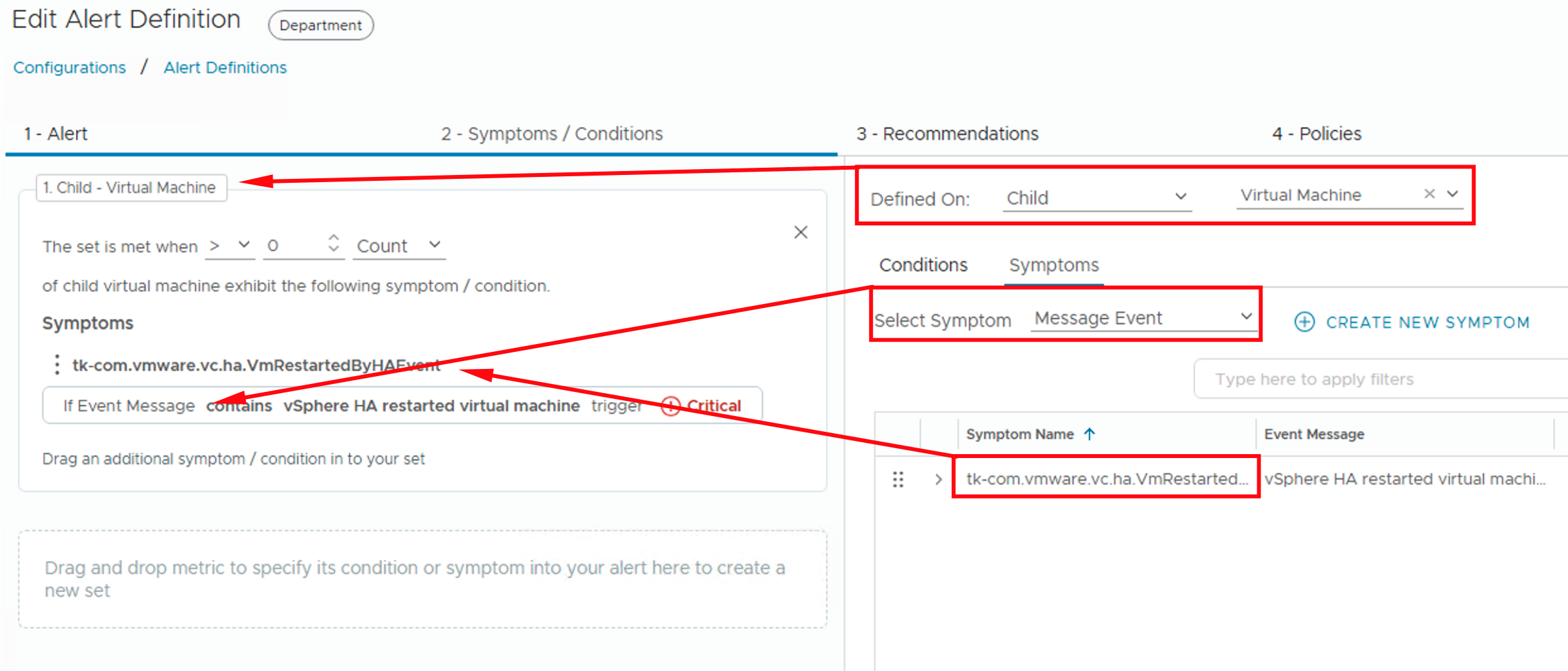
Notification Definition
We can now consolidate these building blocks into a Notification Definition. This Notification will send a REST payload to our endpoint whenever any VM in a predefined Custom Group is affected by an HA event. The JSON body will contain relevant VM information for the group, and can be extended as desired.
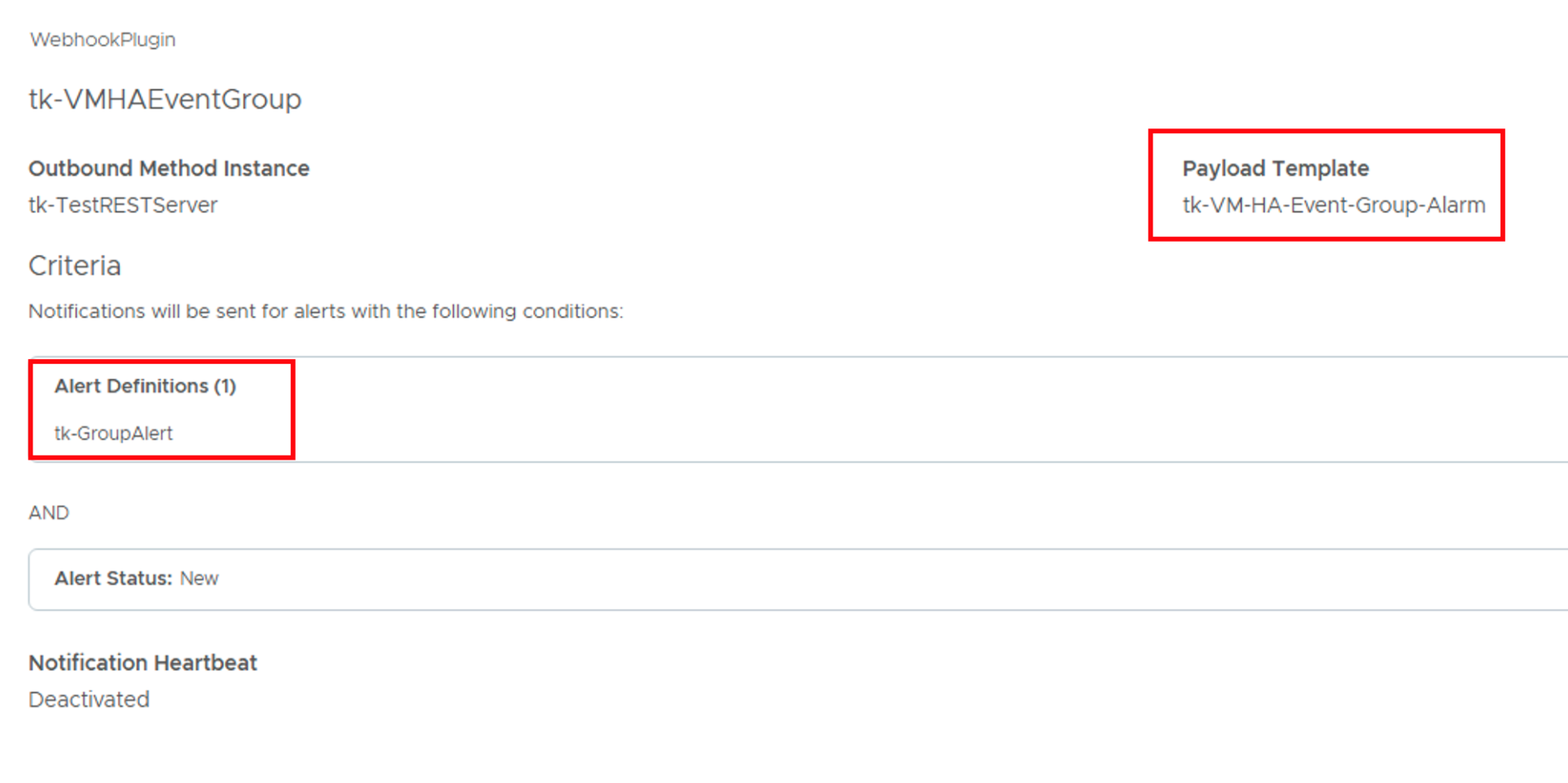
Payload Received
The next screenshot shows the JSON body containing the transmitted data. From the uptime, you can quickly identify which VMs in the group were potentially affected by an HA event. While we could add other metrics, like the VM’s alarm count, this information is already sufficient to specifically focus our investigation on those VMs in VCF Operations.
All configurations and definitions from this post can be found in my Git repo: https://github.com/tkopton/aria-operations-content/tree/main/VM-HA-Event-Group-Notification
Stay safe.
Thomas – https://twitter.com/ThomasKopton