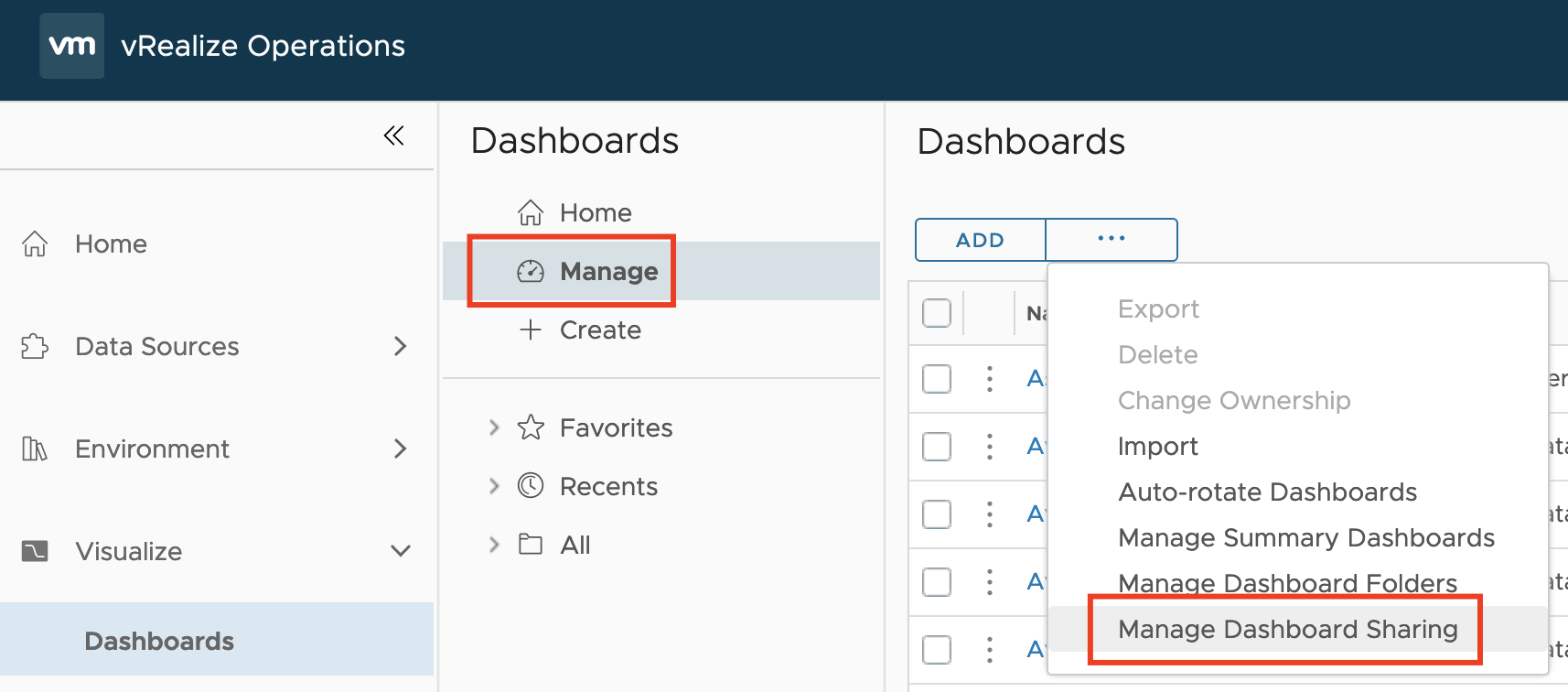
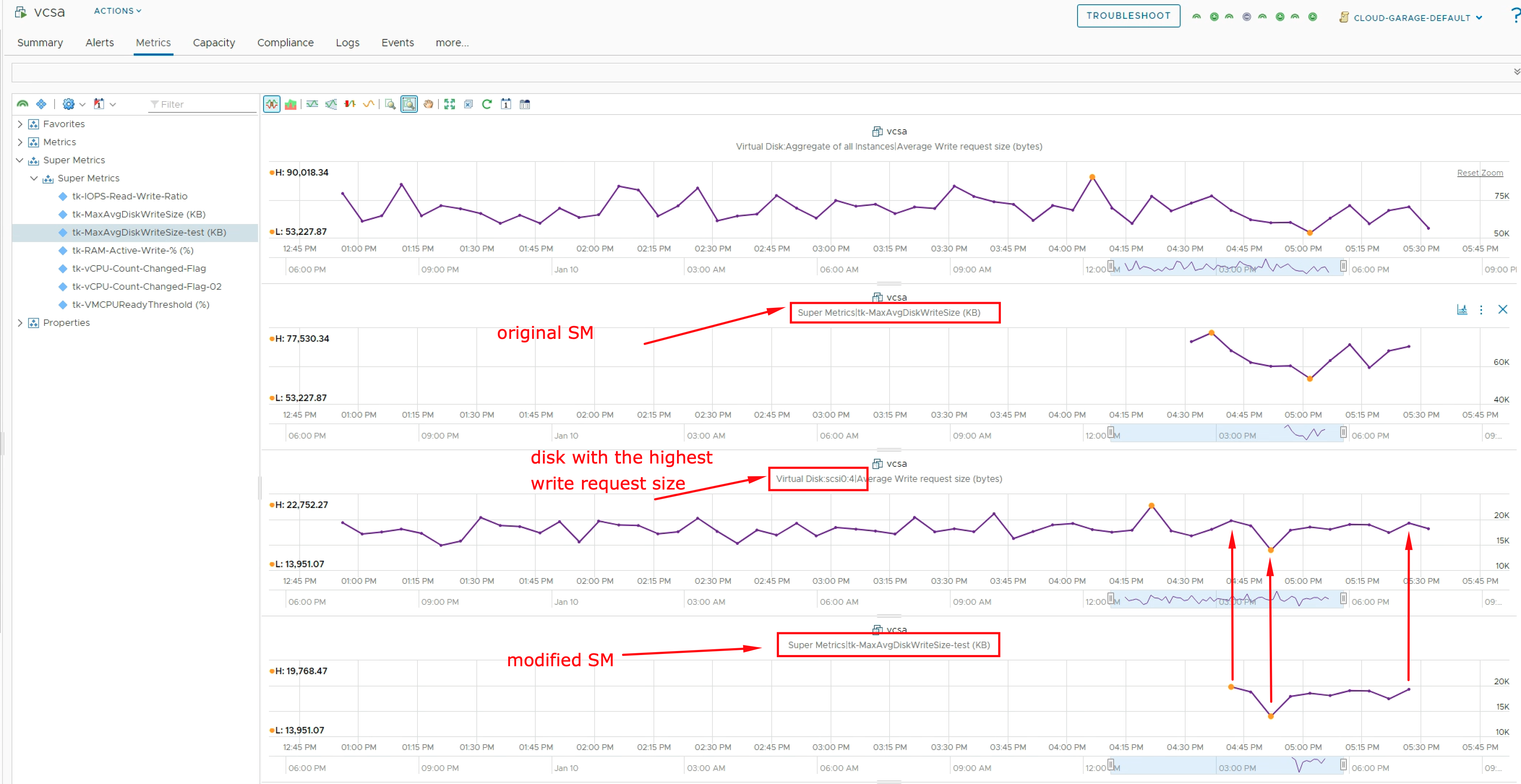
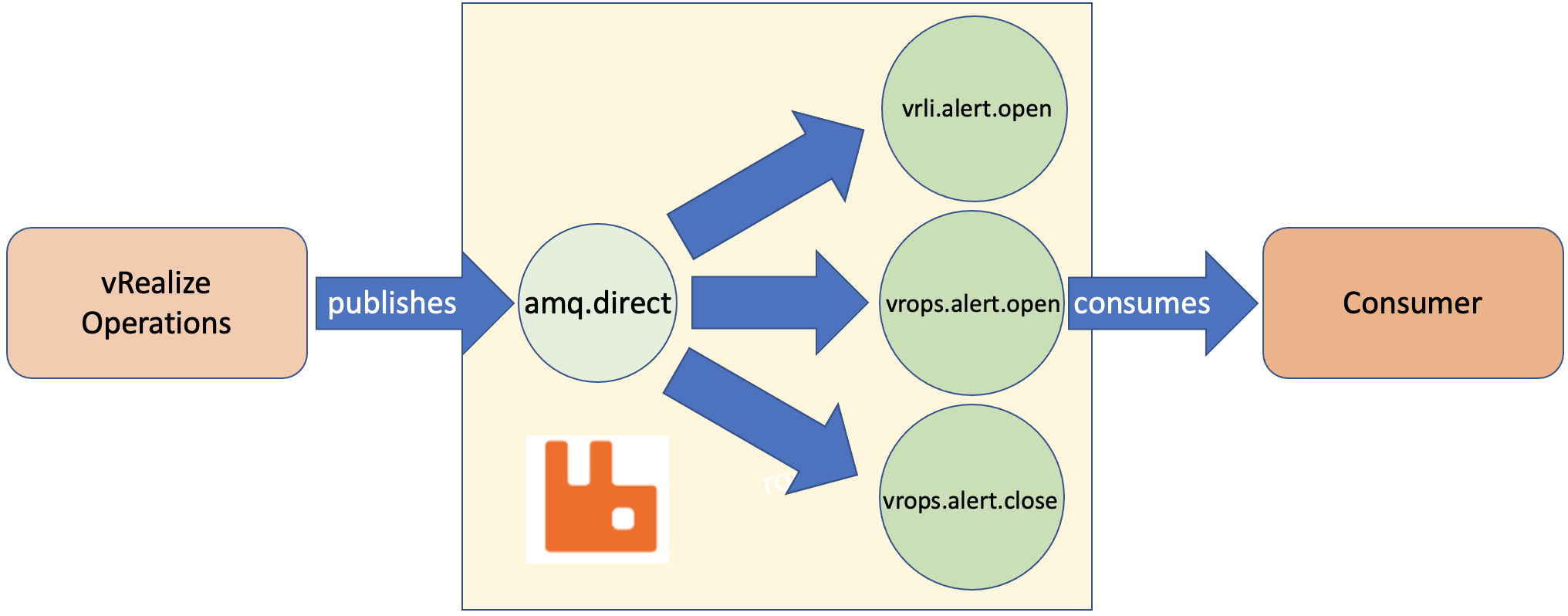
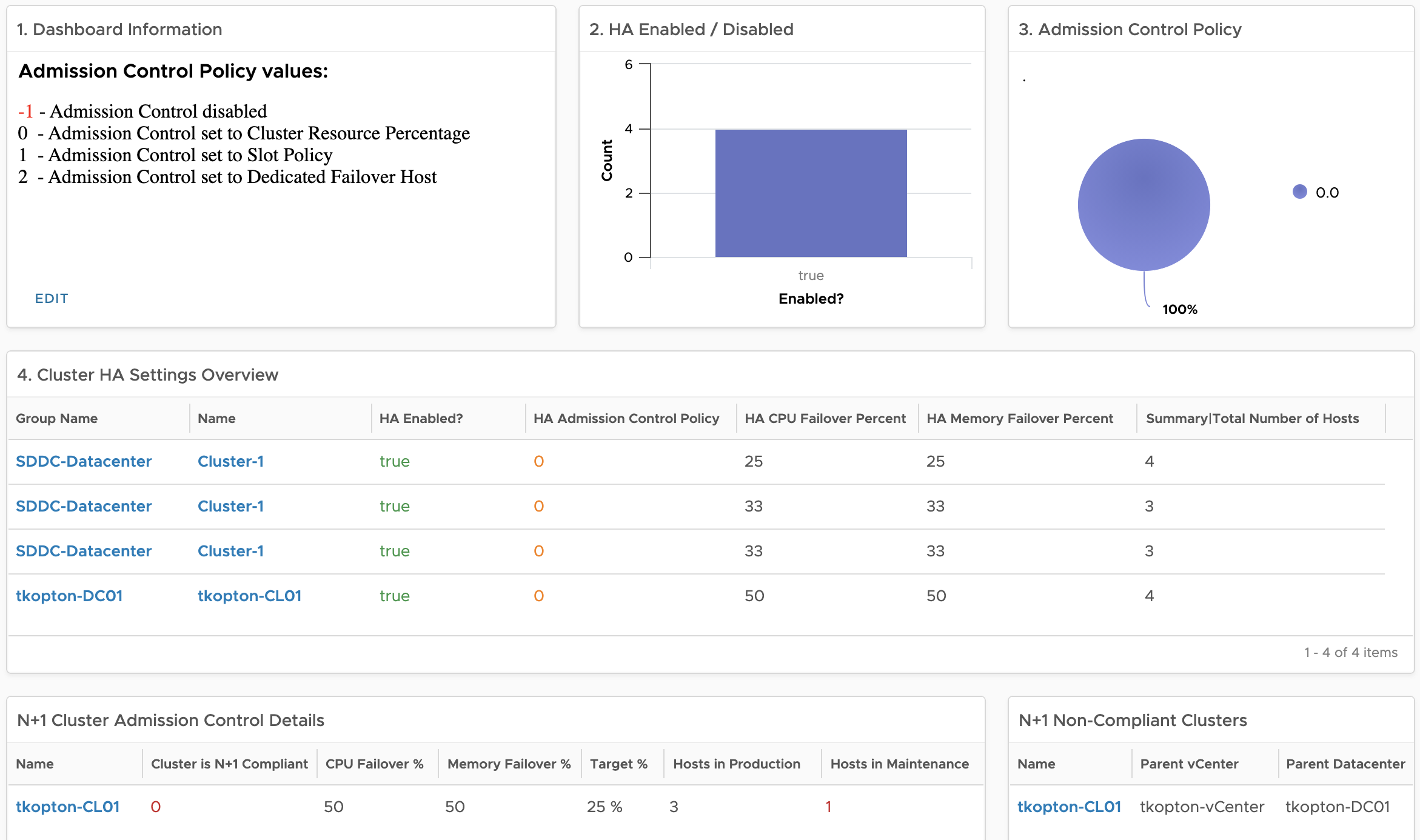
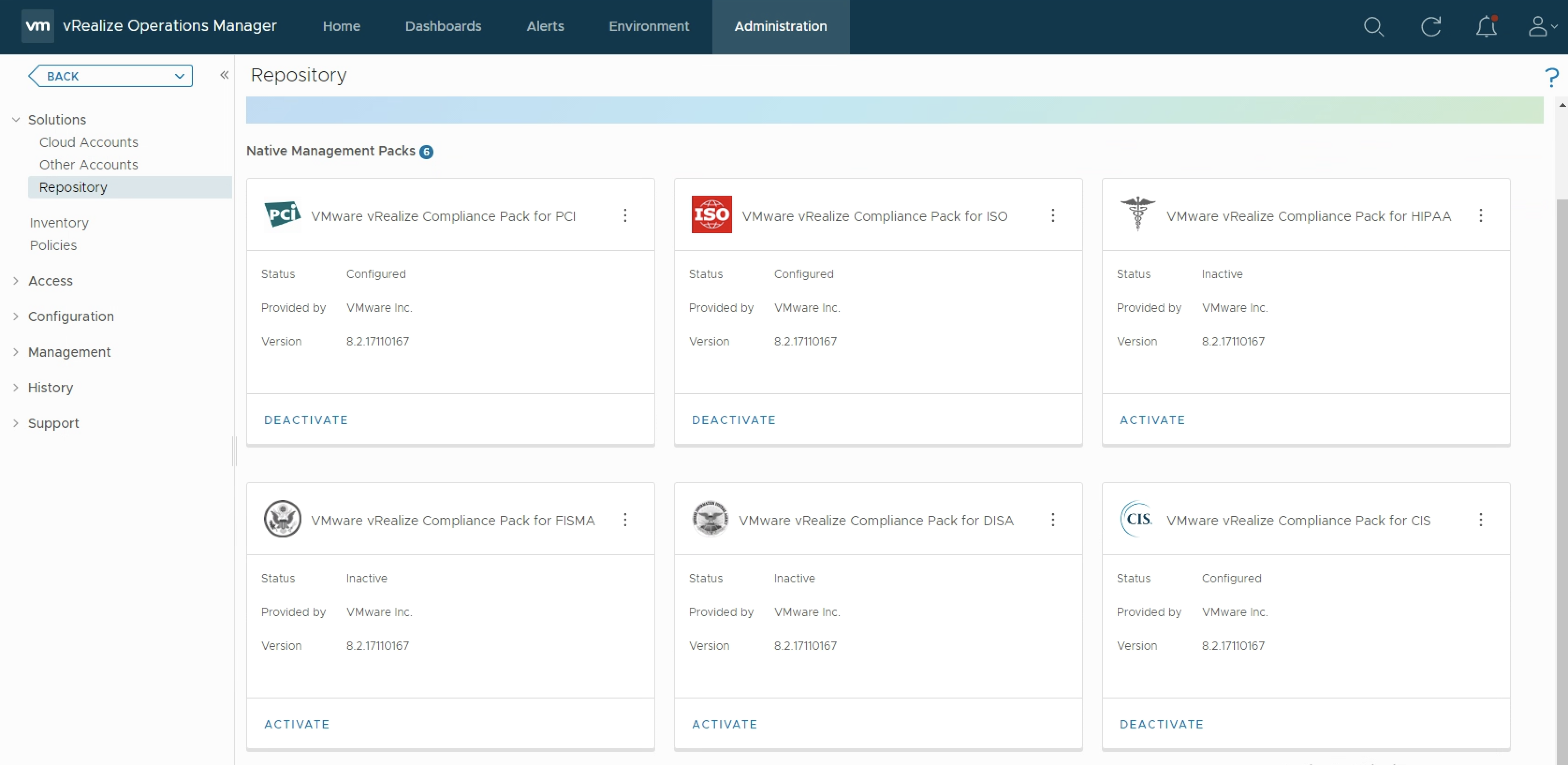
Another question I was asked during my “Meet the Expert – Creating Custom Dashboards” session which I could not answer due to the limited time was: “How to manage access permissions to Aria Operations Dashboards in a way that will allow only specific group of content admins to edit only specific group of dashboards?“ Even …
VMware Explore Follow-up 2 – Aria Operations Dashboard Permissions Management