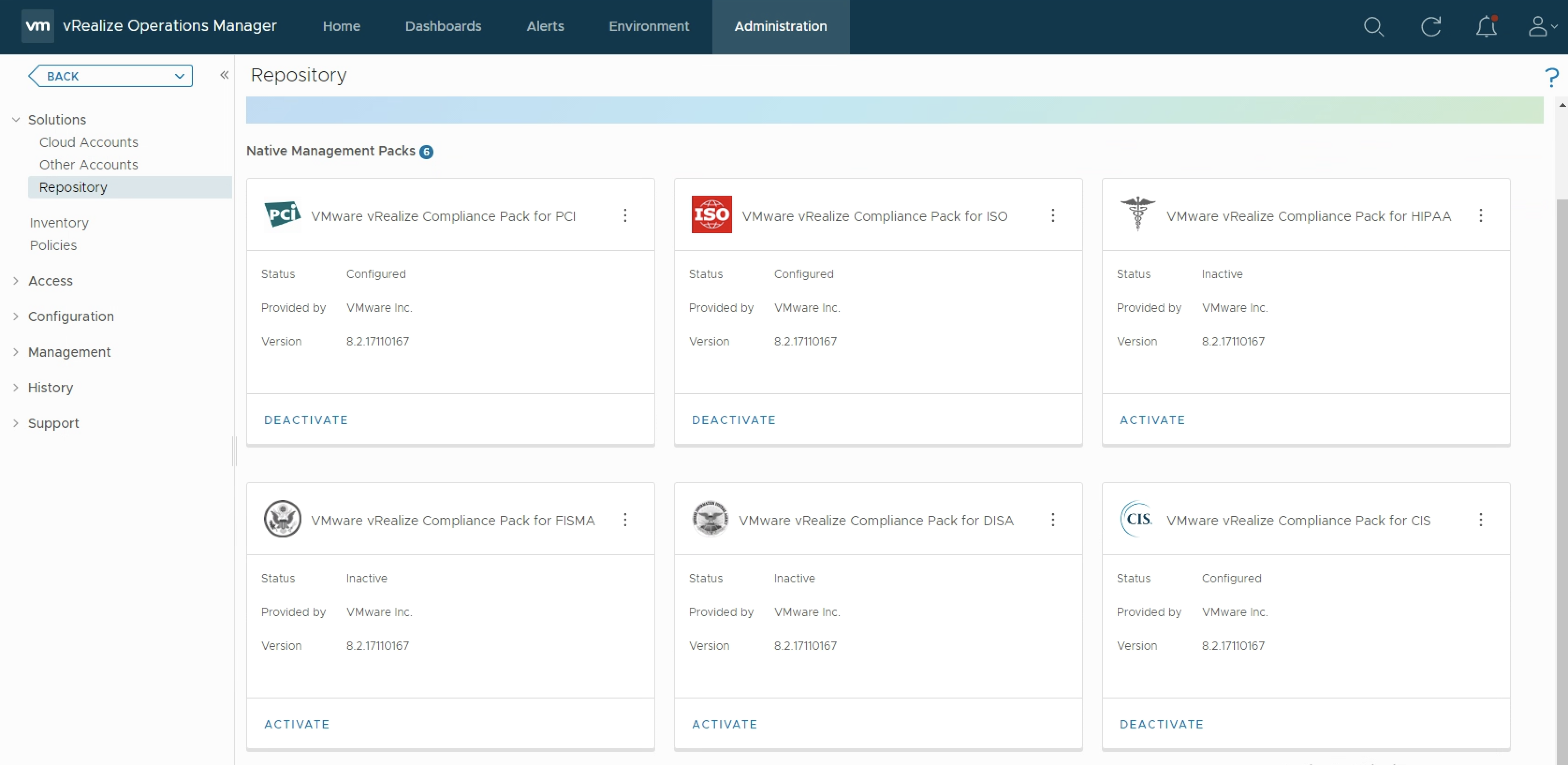
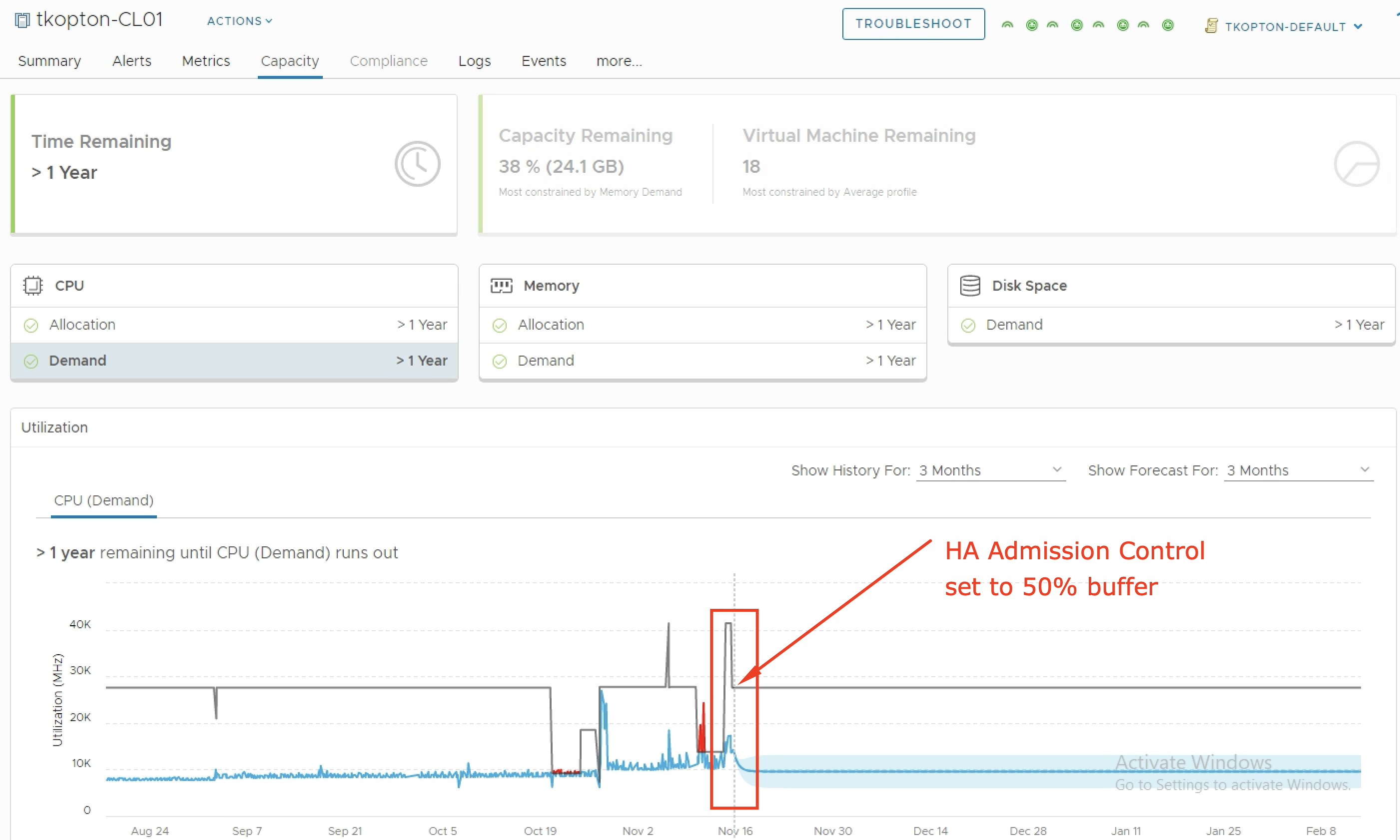
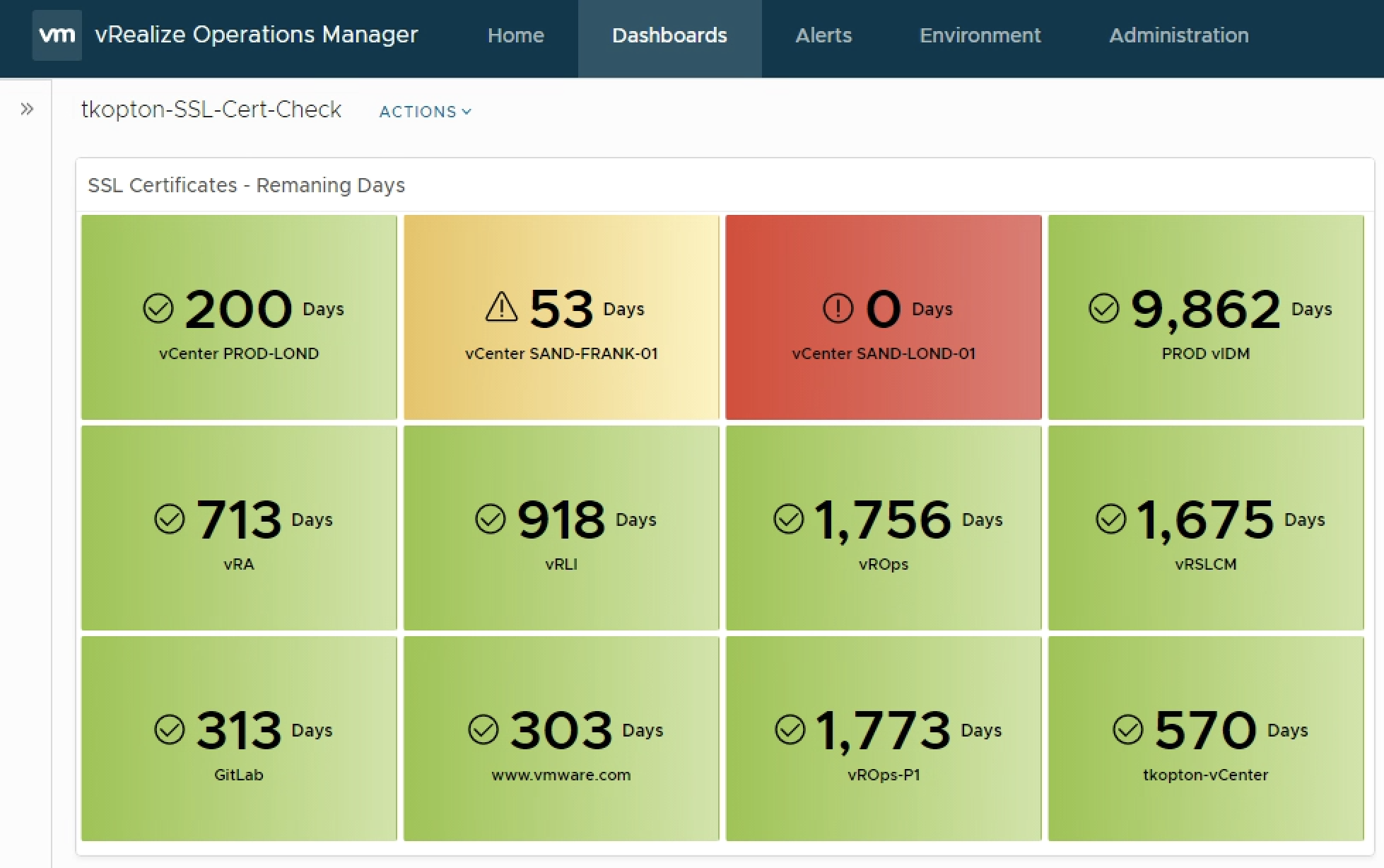
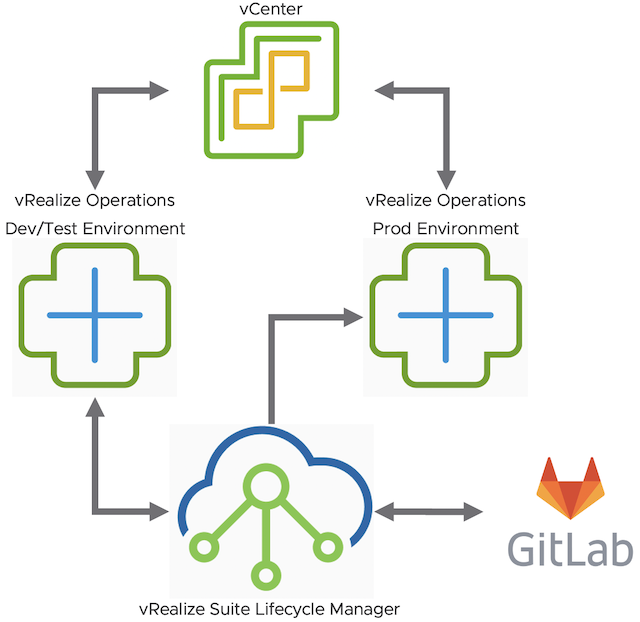
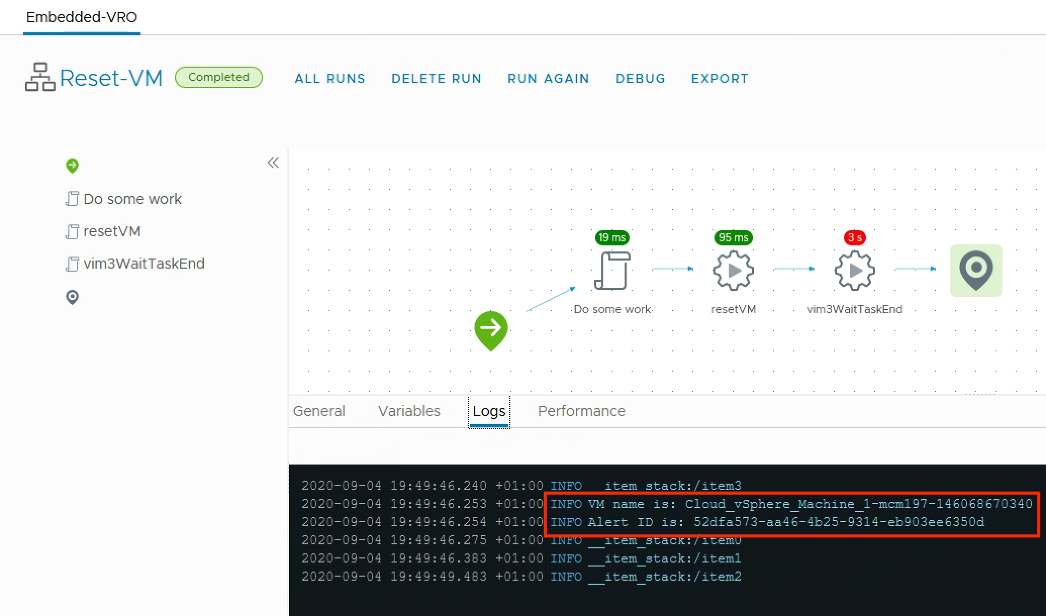
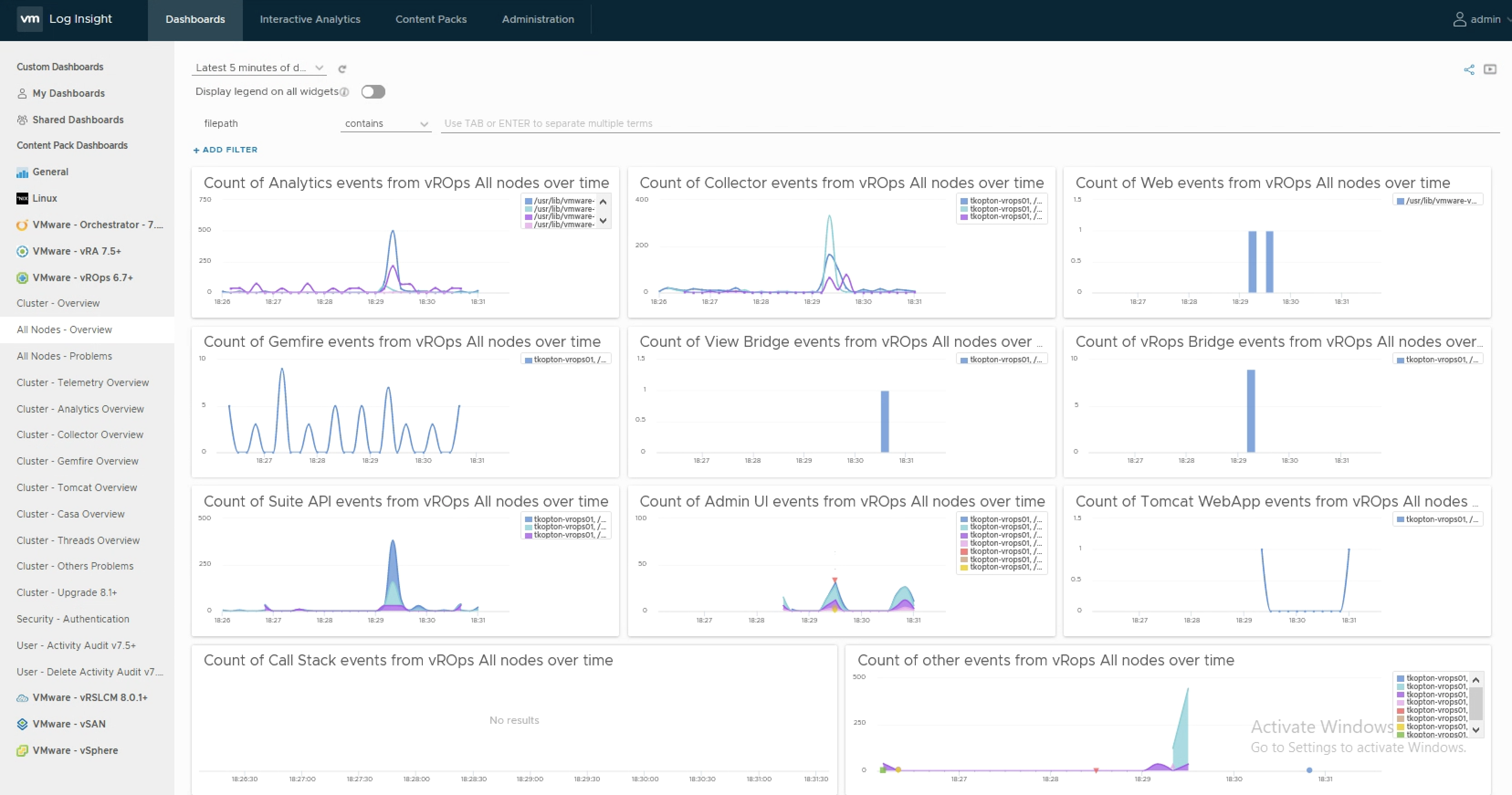
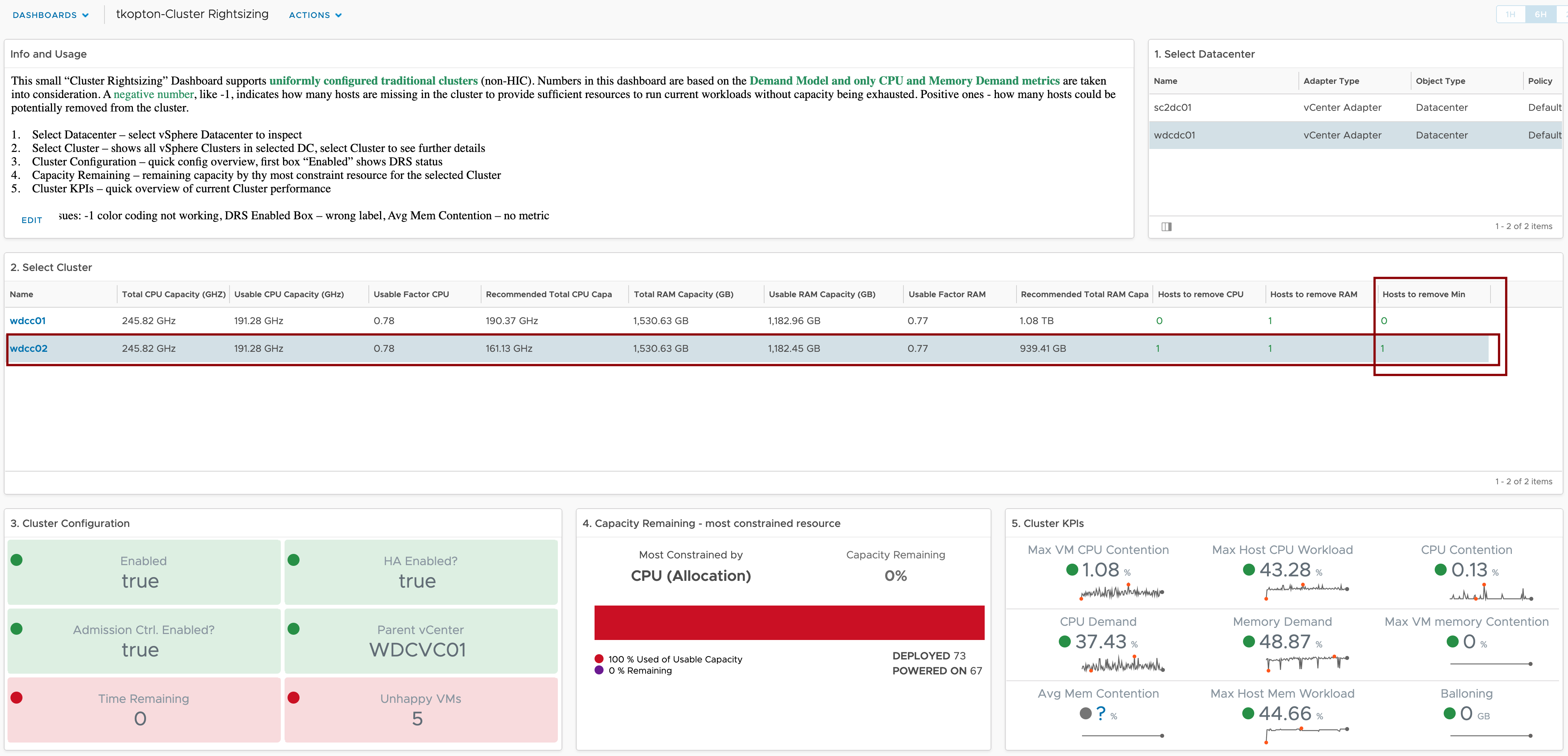
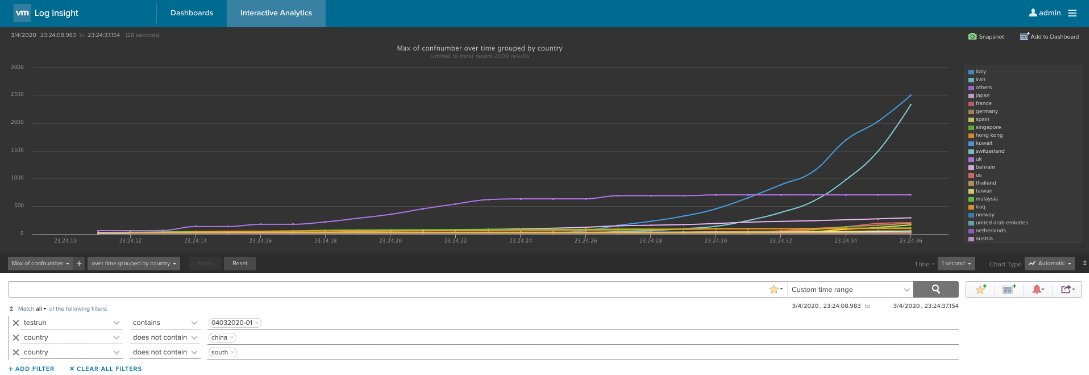
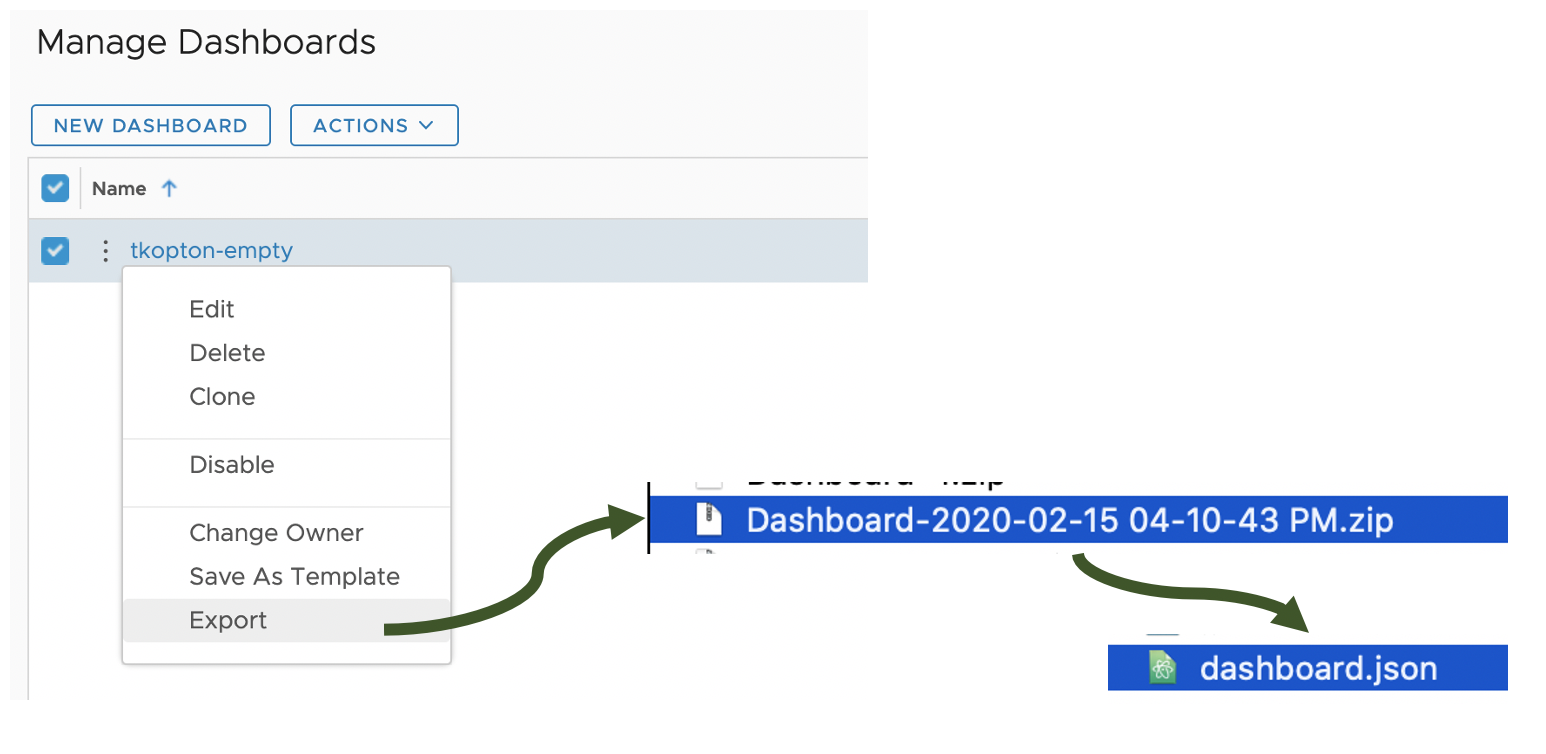
As you probably know vRealize Operations provides several Compliance Packs basically out-of-the-box (“natively”). A simple click on “ACTIVATE” in the “Repository” tab installs all needed components of the Compliance Pack and allows the corresponding regulatory benchmarks to be executed. “Regulatory benchmarks provide solutions for industry standard regulatory compliance requirements to enforce and report on the …
Custom Compliance Management using vRealize Operations